



基于OmniParser的AI智能体交互引擎开发
项目简介
微软的
OmniParser是一个基于纯视觉技术的开源屏幕解析工具,能够将用户界面截图转换为结构化数据,通过结合深度学习模型和OCR技术精准识别可交互元素,并生成语义描述。本项目基于
OmniParser框架,集成多模态模型(视觉解析、语义理解、OCR),通过模块化架构构建可扩展的智能Agent系统,支持用户自定义知识库注入与动态学习机制,实现跨平台界面元素的自主识别与语义化操作。
项目亮点
零代码自然语言交互
用户通过口语化指令直接操控系统/软件/网页,突破传统工作流与模块化编程限制,学习成本大大降低。
多模态智能融合
集成视觉解析
YOLOv8、OCR与NLP,实现界面元素像素级定位与语义化意图理解。
动态知识库引擎
支持私有化数据注入与增量学习,通过RAG框架实现领域知识实时更新,适配各专业场景自动化需求。
技术实现流程
方法一:算力换空间
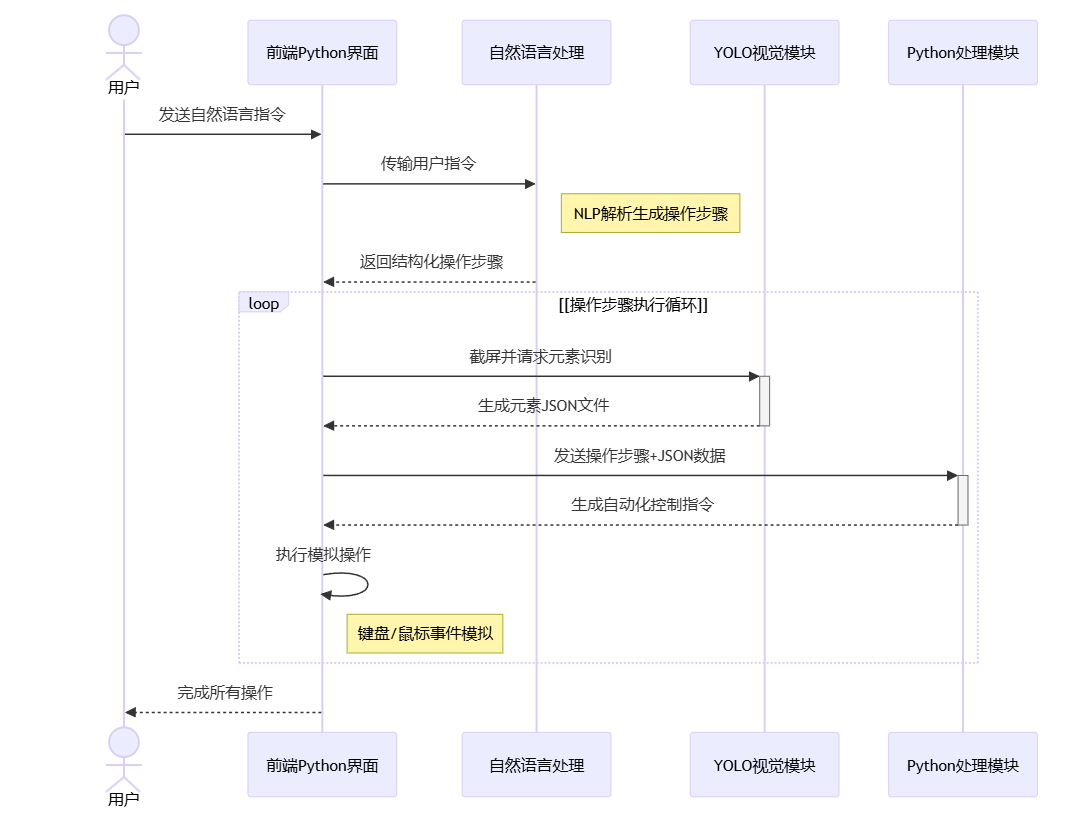
核心优势
多模态融合的智能解析
结合
NLP与CV技术实现双重验证(如指令"点击登录按钮"时既解析语义又实际定位按钮元素)模块间数据耦合度科学:结构化操作树(NLP输出)与元素JSON(CV输出)形成互补验证
闭环容错体系
操作循环(流程图中的loop结构)支持迭代执行:当首次定位失败时触发滚动/缩放等补偿行为
异常状态快照机制:自动保存失败时刻的屏幕截图与系统日志,便于问题溯源
动态适配能力
元素驱动型操作:通过JSON文件中的元素属性动态选择交互方式(如对禁用按钮自动切换备用方案)
分辨率无关设计:基于相对坐标的点击位置计算,适配不同屏幕尺寸
潜在短板
实时性挑战
视觉处理延时:2-5fps的截图频率可能导致动态界面响应滞后(如网页加载未完成时的误判风险)
NLP-CV数据同步成本:跨模态数据对齐需消耗额外计算资源
界面适配风险
视觉识别盲区:
YOLO对渐变/透明/动态特效元素的识别准确率可能下降特殊控件适配:需要定制库支持非标准UI组件(如游戏化界面或3D控件)
调试复杂度
非确定性反馈:相同操作可能因网络延迟或系统负载产生不同的屏幕变化
方法二:空间换算力
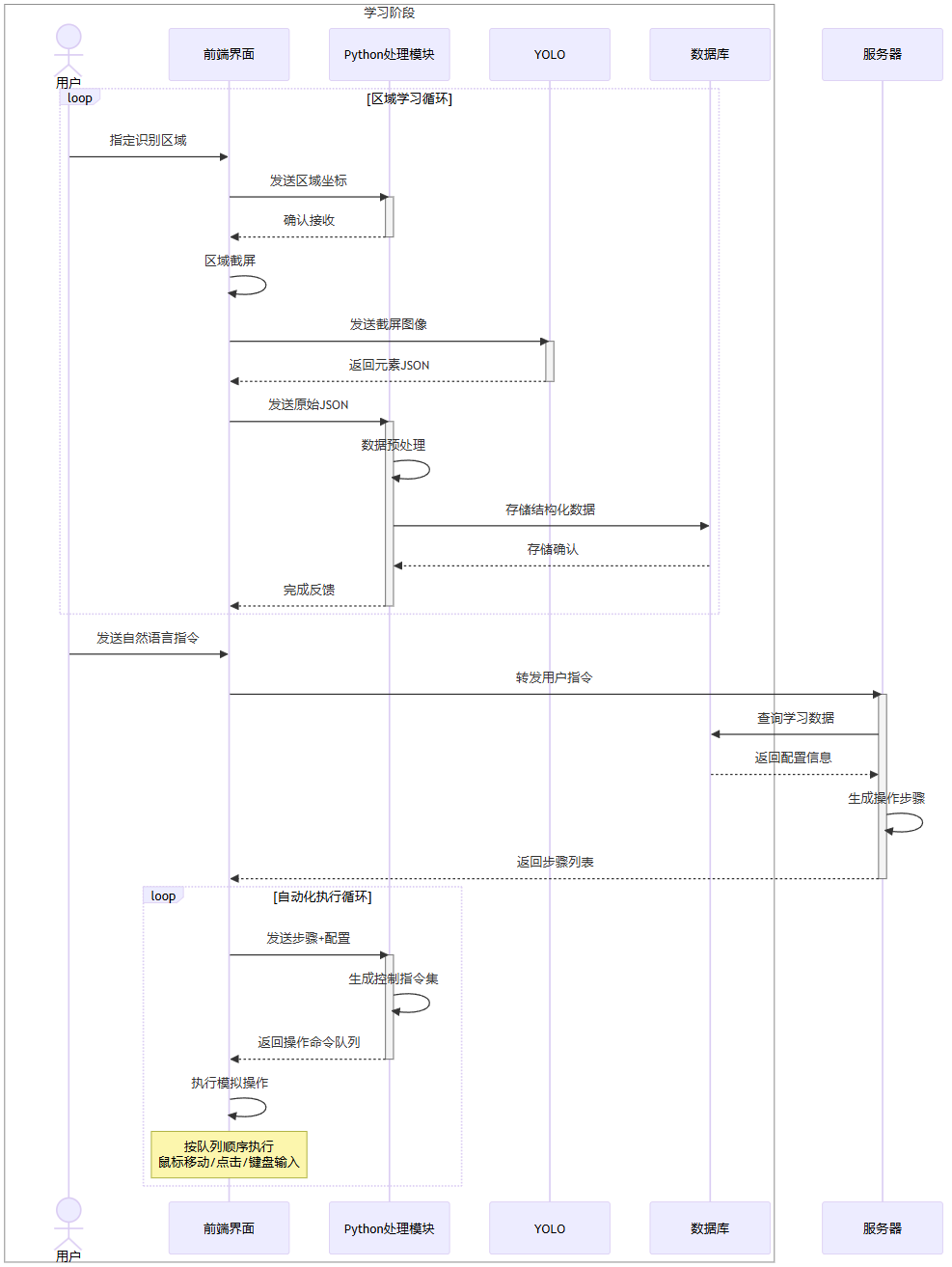
核心优势
分层自治架构
前端界面与
NLP服务器物理隔离,通过API通信实现松耦合(如"发送自然语言指令"与"返回步骤列表")数据库独立承担配置管理与历史记录("查询学习数据"与"存储结构化数据"双通道)
双循环驱动机制
区域学习循环:通过
YOLO的持续反馈("返回元素JSON"→"生成控制指令集")实现动态环境适应自动化执行循环:命令队列机制("按队列顺序执行")确保操作原子性与可追溯性
视觉-操作联动
坐标定位闭环:从"指定识别区域"到"鼠标移动/点击"形成空间映射验证
容错重试设计:"loop"结构支持操作失败时的参数校准(如分辨率适配或元素遮挡处理)
潜在短板
实时性瓶颈
跨模块通信延时:需经历"用户→前端→NLP→数据库→Python→YOLO"的链式传递
视觉处理耗时:"区域截屏→元素JSON"流程受限于
YOLO的推理速度(典型延迟200-500ms)
状态同步风险
界面动态变化可能导致"发送步骤配置"与"执行模拟操作"阶段出现状态不一致
缺乏操作中间态校验(如点击后未及时检测页面跳转)
资源消耗问题
并行运行
YOLO视觉服务与Python自动化模块需要较高GPU/CPU配置数据库频繁存取("存储确认"与"完成反馈")可能引发I/O瓶颈
RAG知识库复杂性
考虑到针对某一应用进行训练时,应用的UI交互方式的多样性,会导致
RAG知识库的体量会指数型增长
方法三:采用OmniParser框架
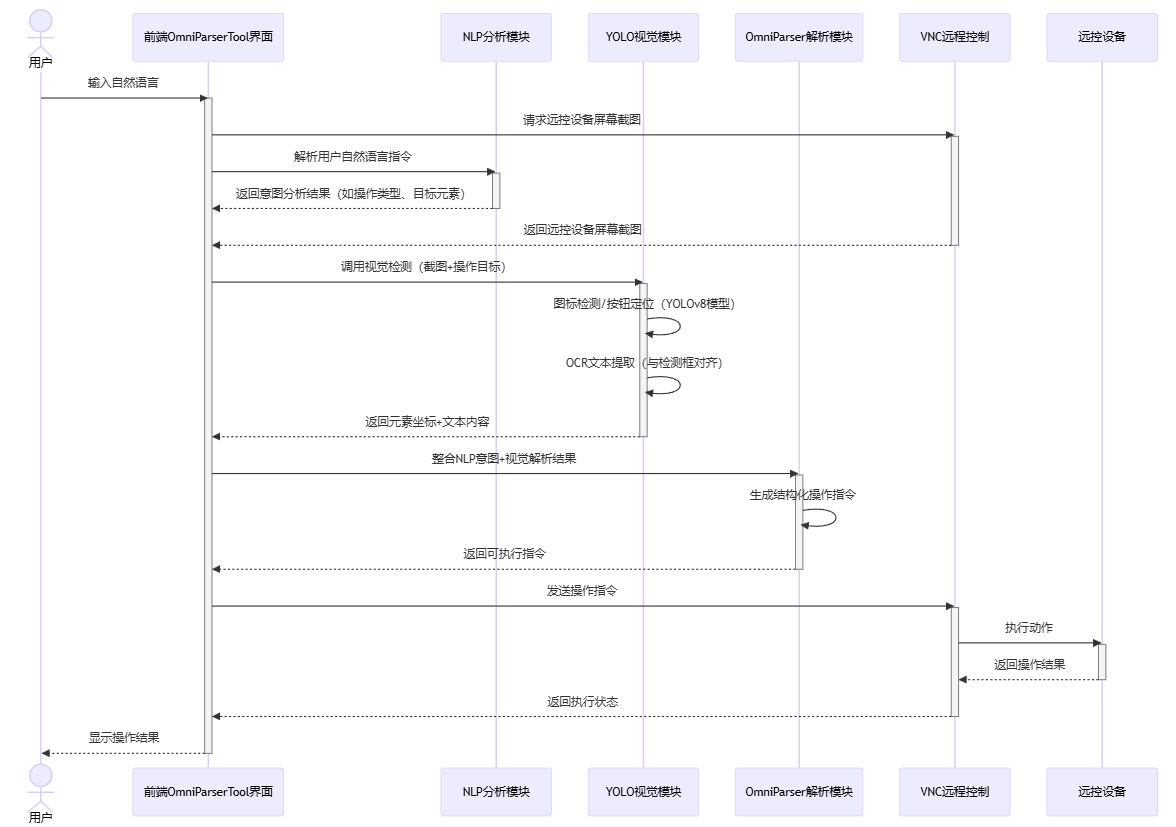
核心优势
多模态协同的自动化处理流程
时序图通过整合自然语言处理(NLP)、计算机视觉(YOLO)和远程控制(VNC)模块,实现了从用户指令到设备操作的端到端自动化。例如,用户输入自然语言后,系统自动触发视觉检测和意图解析,最终生成可执行指令,显著减少了人工干预需求。
模块化设计:各模块分工明确(如NLP负责意图解析、YOLO负责元素定位),便于扩展和维护。
实时反馈:通过VNC实时获取设备屏幕截图,结合视觉检测动态调整操作目标,提升指令的精准性。
高精度与鲁棒性
意图与视觉双重校验:NLP解析用户意图后,YOLO模块通过图标检测和OCR提取文本,双重验证操作目标的位置和内容,避免单一模块的误判。
结构化指令生成:OmniParser解析模块整合语义和视觉结果,生成标准化的操作指令(如点击坐标、输入文本),确保执行逻辑的可靠性。
跨平台与远程控制能力
支持通过VNC协议远程操控设备,适用于物联网、跨系统场景(如远程维护工业设备或移动终端)。
前端界面统一调度各模块,屏蔽底层技术差异,用户无需关注具体实现细节。
潜在短板
复杂度与维护成本高
多模块依赖:任一模块故障(如NLP误解析、YOLO漏检)可能导致全流程中断,调试需逐层排查,耗时较长。
时序敏感性问题:远程设备截图与指令执行的延迟可能引发竞态条件(如界面元素变化后指令失效)。
模型性能瓶颈
NLP泛化能力:自然语言指令的多样性可能超出预设意图分类范围,导致解析失败(如俚语或复杂逻辑指令)。
视觉检测局限:YOLO对低分辨率截图或动态界面(如动画过渡)的检测精度可能下降,影响定位准确性。
扩展性与场景适配挑战
定制化成本高:针对新设备或特殊界面需重新训练视觉模型或调整NLP规则,开发周期较长。
资源消耗大:实时截图传输、模型推理(尤其是YOLOv8)对算力和网络带宽要求较高,可能不适用于边缘设备。
项目结构
系统架构层
前端交互层
OmniParserTool界面(
Vue3+Electron)实时通信模块(
WebSocket+VNC协议)操作日志可视化看板(
ECharts)
业务逻辑层
指令调度中心(
Flask REST API)任务队列管理(
Celery+Redis)设备连接池(
SSH/VNC连接复用)
核心模型层
自然语言处理模块
指令解析引擎(
Deepseek-7B微调)意图分类器(
BERT+ 领域适配)实体抽取组件(
BiLSTM-CRF模型)RAG增强知识库(
FAISS向量检索)
计算机视觉模块
界面元素检测(
YOLOv8s轻量化部署)多语言OCR引擎(
PaddleOCR+LayoutParser)屏幕坐标系转换器(
DPI自适应算法)
指令合成模块
OmniParser核心引擎(
PyTorch规则融合)跨平台指令生成器(
Windows/macOS适配)操作链验证模块(
Selenium兼容测试)
基础设施层
远程控制体系
VNC协议栈(
TigerVNC服务端)设备状态监控(
Prometheus埋点)安全认证模块(
OAuth2.0+ IP白名单)
数据处理管道
截图缓存系统(
Redis Stream)操作日志数据库(
MongoDB时序存储)模型训练数据集(合成UI数据集)
技术栈补充
核心框架:
Python 3.10+Flask+PyTorch 2.0部署架构:
Docker+Kubernetes微服务化运维监控:
Grafana+ELK日志系统测试体系:
Pytest+Appium自动化测试
写在最后
目前我们团队所搭建起来的一些小型服务

- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝