



Agent调研
1.Agent背景/前身
回顾一下LLM(大语言模型)。就是一个聊天机器人,本质上擅长理解文字回答我们的问题。通常再帮我们完成一些简单的事,比如修改文件、回答问题、聊天等一些文字性的处理。但是面对更复杂的需要多步骤执行,跟外界有交互性的任务时就无法完成了。所以很多人早期说“聊天机器人是伪需求”,把这些AI当成一种高级的搜索引擎使用。这种AI无法完成一些高级的任务,于是Agent的概念就很有必要了。
2.核心概念
Agent概念的核心就是要让AI真正实现自主完成任务。简单来说就是当AI收到一个任务的时候,它不仅要自己去想应该怎么做,还得要自己真的去做。与传统AI仅提供建议或单一环节处理不同,智能体需要实现完整的"感知-决策-行动"循环。
Agent -> 代理
所谓代理就是代表人类去完成具体任务的AI。

结合以上的经典定义:
AI Agent就是一种能够感知环境、独立做出决策、并主动执行的人工智能系统
3.Agent四大能力
3.1感知能力
阶段一:文本感知
单纯的大语言模型是依靠海量的文本数据训练出来的,基础的感知方式就是接受用户输入的文本。
阶段二:间接多模态感知
利用OCR这种中间工具,把图片/PDF等转成文本输入给大模型。人们会发现只提取其中的文字势必会少很多信息,比如图片的颜色布局、声音的语气语调。
阶段三:端到端视觉感知
于是2023年OpenAI GPT4有了Vision版本,开启了多模态模型的初阶状态,能够理解图片上的所有信息了颜色、图形等。这个时候大模型就有了视觉感知能力,AI能够识别非文本型信息。
阶段四:端到端多模态感知
2024年GPT又发布了4o,直接把声音、图片这样的多模态数据都喂给大模型,端到端的去训练。AI已经能够理解和识别声音中的语气语调和图片细节的信息。甚至后来还出现能够很好识别视频时序的多模态模型。也就是这个时候大模型的眼睛、耳朵、嘴巴都有了。
总结:
当然也并不是现在是所有的模型都是多模态模型,例如DeepSeek R1就还是一个文本模型。但总之靠大语言模型驱动的Agent已经拥有以上这些感知能力了。
3.2规划能力
最早的时候这些模型回答问题时都是张口就来,一旦遇到稍微复杂的、需要稍微推理一下的问题AI就会“瞎说”,连简单的数字加减法都会算错。这样一定是不行的,俗话说“无谋不成事”。于是就有了......
阶段一:CoT和ToT
CoT(思维链):让模型在给出最终答案之前先主动去拆解一下问题,列出操作步骤。最后将步骤的答案综合起来得出结论。
ToT(思维树):在CoT的基础上又有了ToT思维树这一概念。让这个大模型想好几种不同的思路依次尝试或者选择最好的那个。
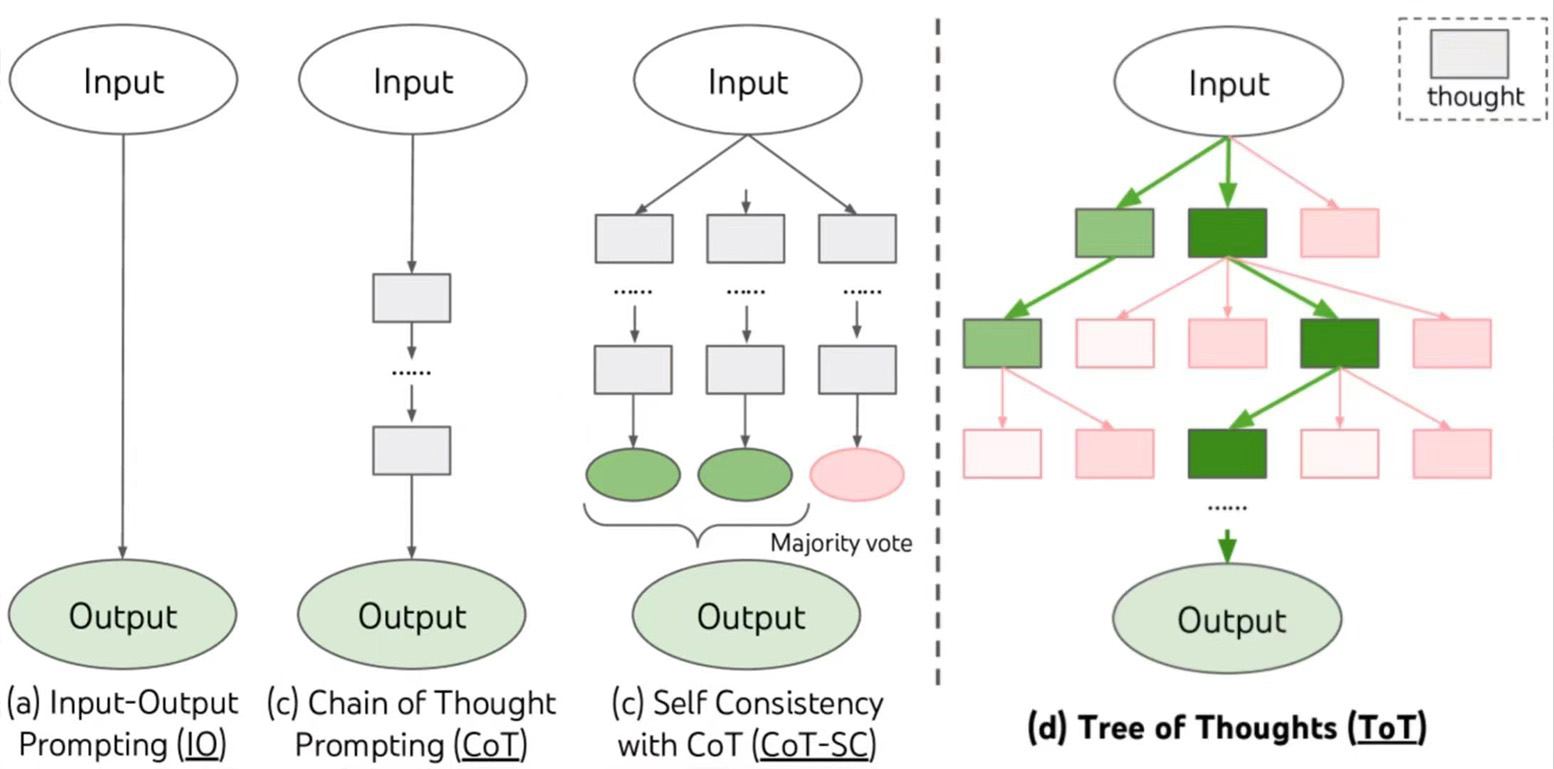
但是用在以前的大语言模型上效果也很一般,因为早期的大模型本质上就不擅长规划,没有针对性的训练过。于是就有了...
阶段二:工作流和多智能体架构
很多个AI各司其职以工作流的形式协作完成任务。
A模型负责规划、B模型负责识别、C模型负责验证...这种称为Multi Agent多智能体架构(扣子、Dify)
但是!治标不治本。中间的步骤都是我们人为设定好的一旦换了新任务就还得重新设计。
阶段三:专门推理模型
所以为了让大模型能真正的有自主规划的能力能处理更复杂的思考OpenAI2024年研究并发布了o1。也就是让大模型内化学会了在每一次回答问题之前都有一个自主推理的过程——thinking。
阶段四:模型即为Agent
基于这些问题2025年2月2日OpenAI出了一个Deep Research,它背后用的实际上四端到端训练过后的o3模型。这意味着是模型它在自主决定什么时候我要去搜一下信息,什么时候我应该整理一下现在的信息,什么时候我又应该进入深度的搜索,再分析总结。整个过程完全是它自己控制的,并不是依赖预先设计好的工作流或者是人为指定的步骤。
总结:Agent规划能力演化
初步规划能力的萌芽(CoT与ToT)
人为干预(工作流和多智能体架构)
专门推理模型(OpenAI的O1和R1)
端到端训练引出“模型即为Agent”(DeepResearch)
3.3行动能力
方式一:基础调用方式 - 调用API
研究者通过提供案例去做监督微调(SFT),让模型学会去自主调用工具。
在合适的进程中生成一段API调用文本,比如需要处理的内容、参数等写成json文件的格式。这种方式名为Function Calling大模型函数调用。
现在不少Agent搭建平台就是自己内含有不少API工具,以供快速调用。但是API调用也有明显的局限性,现实中不是所有的东西都有API。
方式二:更复杂的行动 - 直接学人类操控电脑
2024年10月Anthropic发布了Computer use是市面上第一个能够操控电脑的AI Agent。它训练大模型从视觉上就能看懂这个电脑屏幕,可以点击和操作电脑。据统计根据命令操控电脑人类的成功率是70%而Computer use仅有15%左右,还是一个非常初阶的实验模型。不过它其实也是直接的去训练模型来理解屏幕像素的一个能力。
但如果退而求其次,只让大模型操控浏览器的话,会更好搞定。所以在Computer use之后就有了Browser use——用传统的网页自动化工具比如说playwright间接的实现了模型控制浏览器的能力。这也就是现在市面上大部分Agent的前身(也是Manus的核心模型)。
方式三:标准化接口 - MCP(模型上下文协议)
后来人们又发现每个工具都要单独去接入、单独去开发实在是太麻烦了。于是Anthropic在2024年11月推出了一个重要协议MCP(模型上下文协议)。
原本大模型调用API是一个工具对应一个Key。工具和Key都还需要自己造。MCP就像一个多孔TypeC转接头要求所有人都按照这个规格来做接口,用什么工具直接往上插就行。
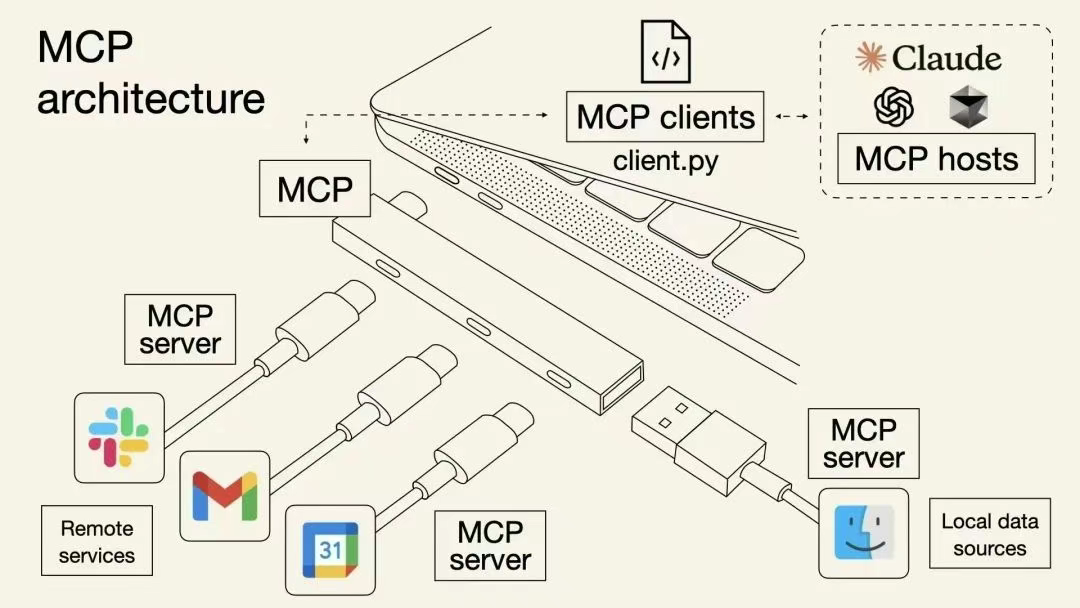
这个规矩一统一就会有很多现成的以MCP为协议的工具,就可以实现快速调用了。
大胆猜测以后再开发任何的软件网页其功能都要支持AI直接调用
3.4记忆能力
方式一:短期记忆
早期大语言模型受限于有限的上下文窗口(通常4k tokens以内),在处理长程文本依赖和多轮对话时存在显著记忆衰减。为突破此瓶颈,主要厂商竞相通过注意力机制优化与并行计算架构扩展上下文窗口,推动模型逐步实现32k至200k tokens的上下文处理能力,显著提升长文档语义分析与持续性对话的连贯性。
方式二:长期记忆
但在一些场景一些特定的文本我们不想让AI忘记。
所以还有一个方案叫RAG(检索增强生成)。把大模型需要记住的知识事先存到一个外部的向上数据库中,每一次用户需要的时候再去里面找有没有相关的内容。这种方法也能有效的减少AI乱编的一些幻觉问题。
方式三:即时记忆
Agent要在执行任务的过程中产生的步骤、数据、文档等也是需要被记住的,所以中途要对前面发生的事做一定的总结存储起来,在后续过程中如果有需要就去查找。这样就形成了Agent的记忆模块。比如说DeepSeek开发的NSA(稀疏注意力机制)。
4.Agent发展现状
我们能看到Agent的能力正在稳步螺旋式上升,从23年开始研究人员就没有停止过对Agent的探索和实验。从23年初GPT3.5刚发布,就有了AutoGPT、BabyAGI、斯坦福小镇、微软的TinyTroupe这些实验项目。所以在当前Agent所需要的这个能力范围内,其实已经有了一些优秀的Agent产品了。其中最成熟可用的就是编程类Agent了,也都支持从一个需求出发AI自己写、自己改、自己创建文件、自己部署网页之类的功能。其次就是Deep research这样的调查Agent,能够进一步操控虚拟电脑完成一些复杂的任务。当然还有一些普通人用不上但是在特定行业内用的非常好的,比如医疗Agent、数据分析Agent、风险评估Agent等。
5.Manus实测
5.1概括
中国团队Monica于2025年3月发布的Manus,宣称是全球首个全自主通用AI智能体,其核心突破在于实现“思考-规划-执行”闭环 。该产品通过多智能体协作架构,能自主完成简历筛选、股票分析、旅行规划等51类复杂任务,并在GAIA基准测试中超越OpenAI模型。发布后迅速引发资本市场震荡,带动150余只AI概念股涨停,内测邀请码被炒至数万元 ,但技术门槛争议与过度营销质疑也随之浮现 。

5.2操作流程
任务:访问 http://sofascore.com,获取过去6个月NBA比赛的数据,制作一个网站,显示得分最高的球员的统计数据。
写todo list
分配任务
搜索信息
浏览网页信息
记录信息
记录进度
搜集素材
开发网站
部署网站
5.3操作流程核心特点解析
人类思维模拟:
体统模仿人类的工作习惯:接到任务先做计划、边执行边调整、完成后检查成果。就像经验丰富的秘书处理老板交代的复杂事项。
离手式操作:
用户只需下达指令,系统在云端独立完成所有步骤,支持中途打断修改需求。如同把任务装进“智能快递箱”,完成后直接验收成果。
记忆进化功能:
系统会记住用户的偏好(如喜欢表格呈现数据),下次自动优化流程。错误操作会被记录,避免重复犯错。
多线程协作:
不同任务模块并行处理,如同同时进行数据分析和网站框架搭建,效率提升3倍以上。
5.4操作特性评估
优势:
多任务并行处理能力(如同时执行数据抓取与代码生成)、端到端闭环消除人工干预、智能容错机制(错误操作自动回滚)
缺陷:
长流程任务响应延迟明显(生成分析报告需40分钟)、可定制性受限(无法修改预设流程逻辑)、隐私焦虑(操作全程依赖云端传输)
5.5Manus技术架构
6.“通用Agent“总结
在实用性和效果上OpenManus和OWL只是比较初期的实验项目,适合大家交流学习,其功能效果并不好。那Manus其实也是一个尝试通用的实验性产品。实际上可用的程度还是非常有限的,远远没有到社交平台上非常夸张的程度。但是用它做一些相对没那么复杂和严谨的博眼球的例如小游戏、小网页也是可以的。在真正的生产上,还是垂直类的Agent更胜一筹。
7.展望未来
一个真正好用的Agent产品之所以能够出现,必然是建立在大模型自身的智能水平提升和基础设施完善的前提之上的。像最早ChatGPT的出现也正是数据、算力和长期研究积累到位之后的产物。所以如果我们回头去看过去的几年Agent也正在经历类似的阶段——基础模型能力的提高、工具能力的建设、RAG质量的提升甚至算力成本的降低、用户需求的明确、开发门槛的降低、社区的壮大...这都像一堆引线在今年交汇在一起点燃Agent落地的火焰。

- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝